Intégrer l'IA dans votre entreprise
Nos équipes vous accompagnent dans l'intégration de modèles comme Claude au sein de vos processus métiers.


Anthropic vient de déployer Claude Opus 4.7, le 16 avril 2026.
Deux mois après Opus 4.6, une semaine après l'annonce très médiatisée de Claude Mythos Preview, la firme américaine ne ralentit pas.
Et cette fois, les changements ne sont pas cosmétiques.
Meilleure vision, suivi d'instructions plus rigoureux, capacité à travailler en autonomie sur des tâches longues et complexes : Opus 4.7 marque un vrai pas en avant pour les entreprises qui utilisent l'IA au quotidien.
Voici ce que ça signifie.
Deux mois après les sorties d'Opus 4.6 et de Sonnet 4.6, et une semaine après avoir dévoilé Claude Mythos Preview, Anthropic présente Claude Opus 4.7.
Le timing n'est pas anodin.
Mythos Preview reste le modèle le plus puissant d'Anthropic, mais Opus 4.7 affiche de meilleurs résultats qu'Opus 4.6 sur l'ensemble des benchmarks.
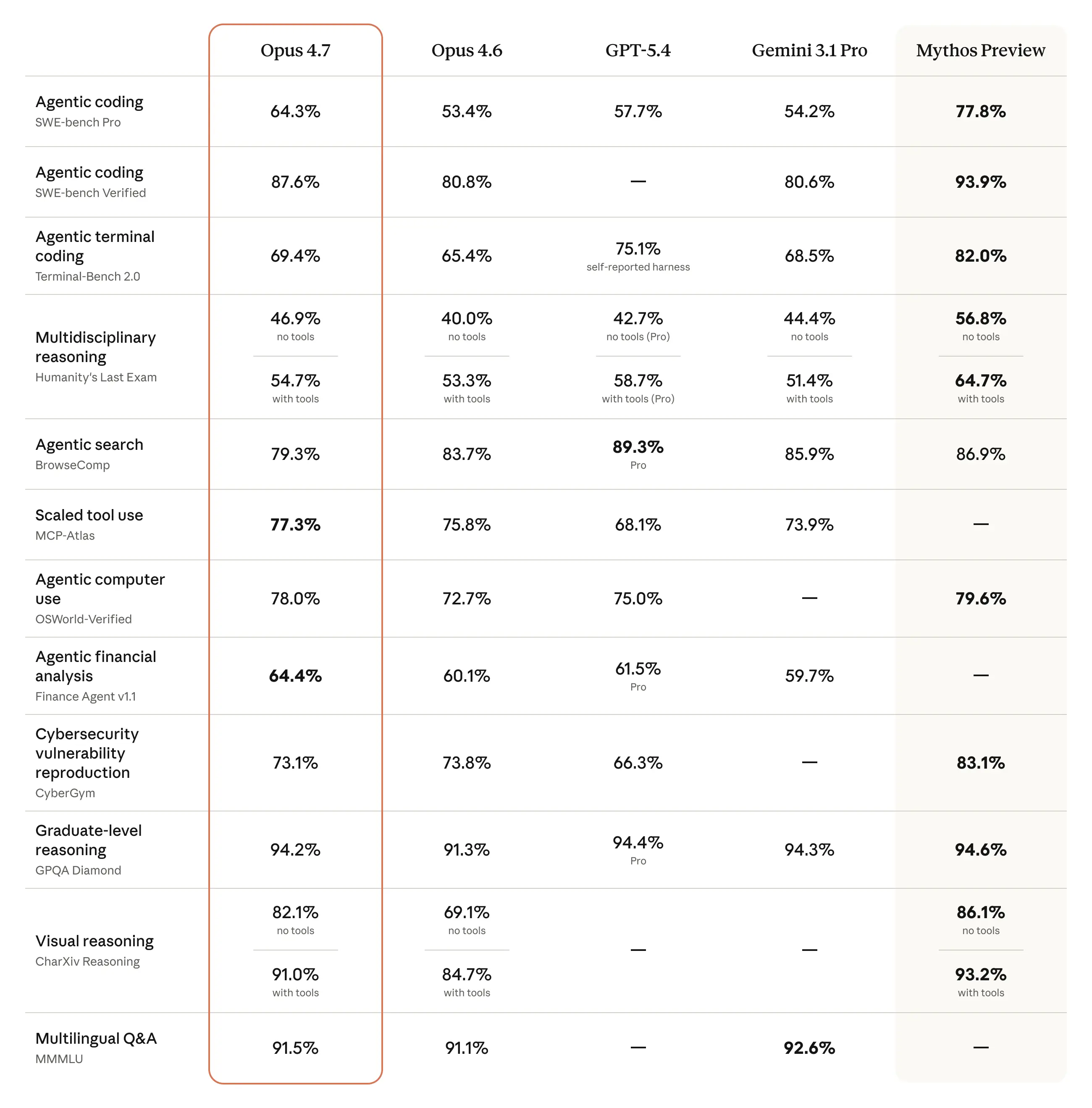
Ce positionnement est délibéré : Mythos est encore réservé à un consortium restreint d'entreprises partenaires dans le cadre du Project Glasswing, pour des raisons de sécurité.
Opus 4.7, lui, est disponible pour tout le monde.
Opus 4.7 n'est pas le modèle le plus puissant d'Anthropic, mais c'est le meilleur LLM accessible au grand public aujourd'hui.
Il est disponible sur l'ensemble des produits Claude, l'API, Amazon Bedrock, Google Cloud Vertex AI et Microsoft Foundry.
Les tarifs restent identiques à Opus 4.6 : 5 dollars par million de tokens en entrée et 25 dollars par million en sortie.

C'est probablement la nouveauté la plus impactante pour les usages métiers.
Opus 4.7 accepte désormais des images jusqu'à 2 576 pixels sur le bord long (environ 3,75 mégapixels), soit plus de trois fois la résolution prise en charge par les modèles précédents.
Pourquoi c'est important ?
Parce que la plupart des usages réels de l'IA impliquent des visuels : captures d'écran de logiciels, maquettes web, diagrammes techniques, tableaux Excel photographiés...
Avec l'ancienne résolution, les agents IA pouvaient manquer des détails critiques.
Cette évolution profite notamment aux agents IA agissant directement sur ordinateur, qui doivent lire des captures d'écran denses, aux tâches d'extraction de données depuis des diagrammes complexes ou de travail à partir de maquettes haute fidélité.
Pour les entreprises qui utilisent l'intelligence artificielle pour automatiser des workflows visuels, c'est un changement de niveau.
Opus 4.7 est nettement plus performant dans le suivi d'instructions.
Il gère les tâches complexes de longue durée avec rigueur et constance, suit les instructions avec précision et trouve des moyens de vérifier ses propres résultats avant de les soumettre.
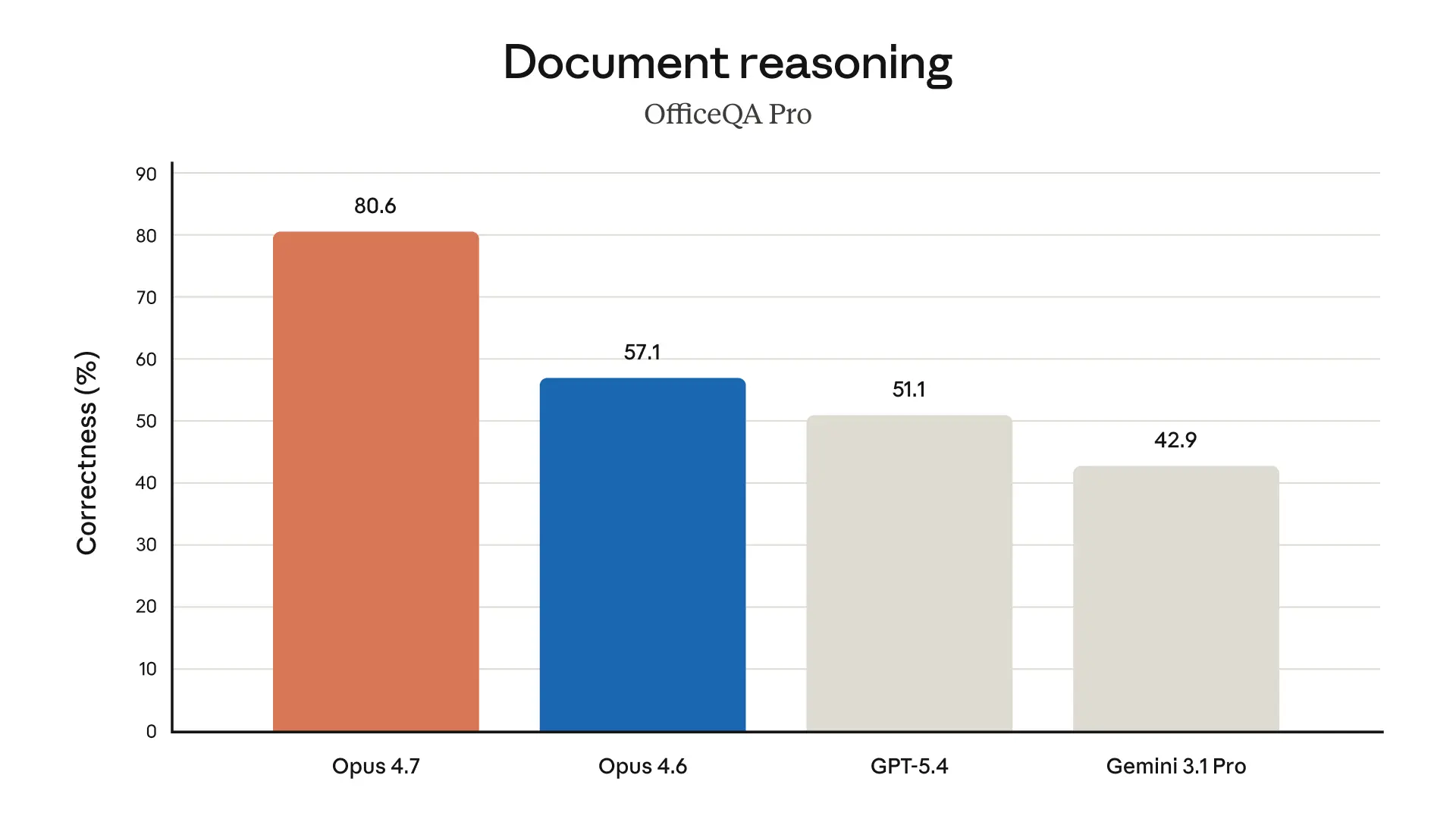
Dites-lui d'analyser 50 documents et de produire un tableau synthétique dans un format précis.
Il le fera.
Sans approximation, sans liberté créative non sollicitée.
Ce progrès a une conséquence pratique importante qu'Anthropic signale explicitement : les prompts écrits pour des modèles antérieurs peuvent désormais produire des résultats inattendus, le modèle les interprétant de manière plus littérale.
Si vous utilisez des prompts optimisés pour Opus 4.6, prévoyez un temps de réajustement.
Les retours des entreprises ayant eu accès anticipé sont éloquents.
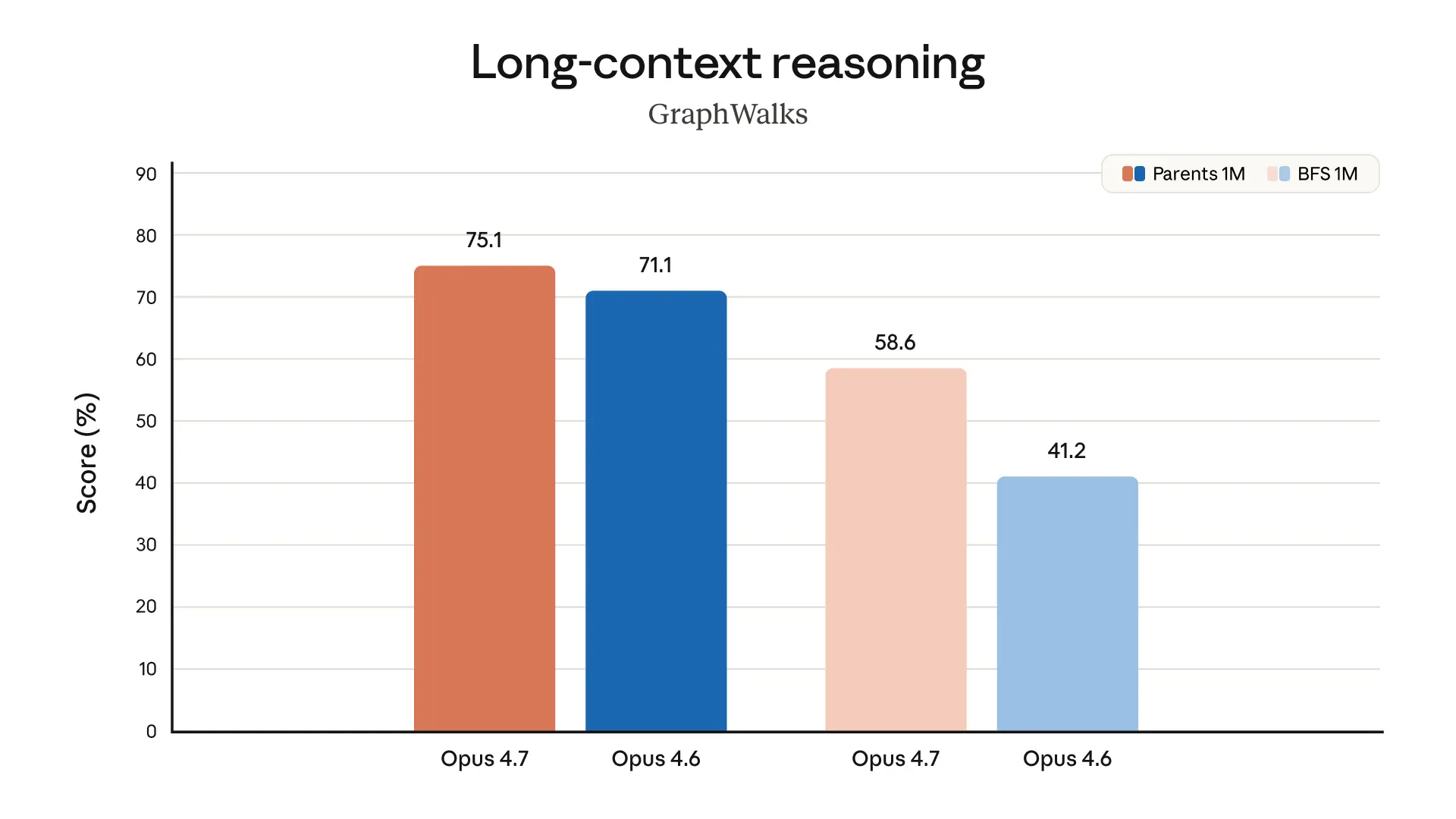
Sur un benchmark interne de 93 tâches de codage, Opus 4.7 a amélioré le taux de résolution de 13% par rapport à Opus 4.6, incluant quatre tâches qu'Opus 4.6 et Sonnet 4.6 ne pouvaient pas résoudre.
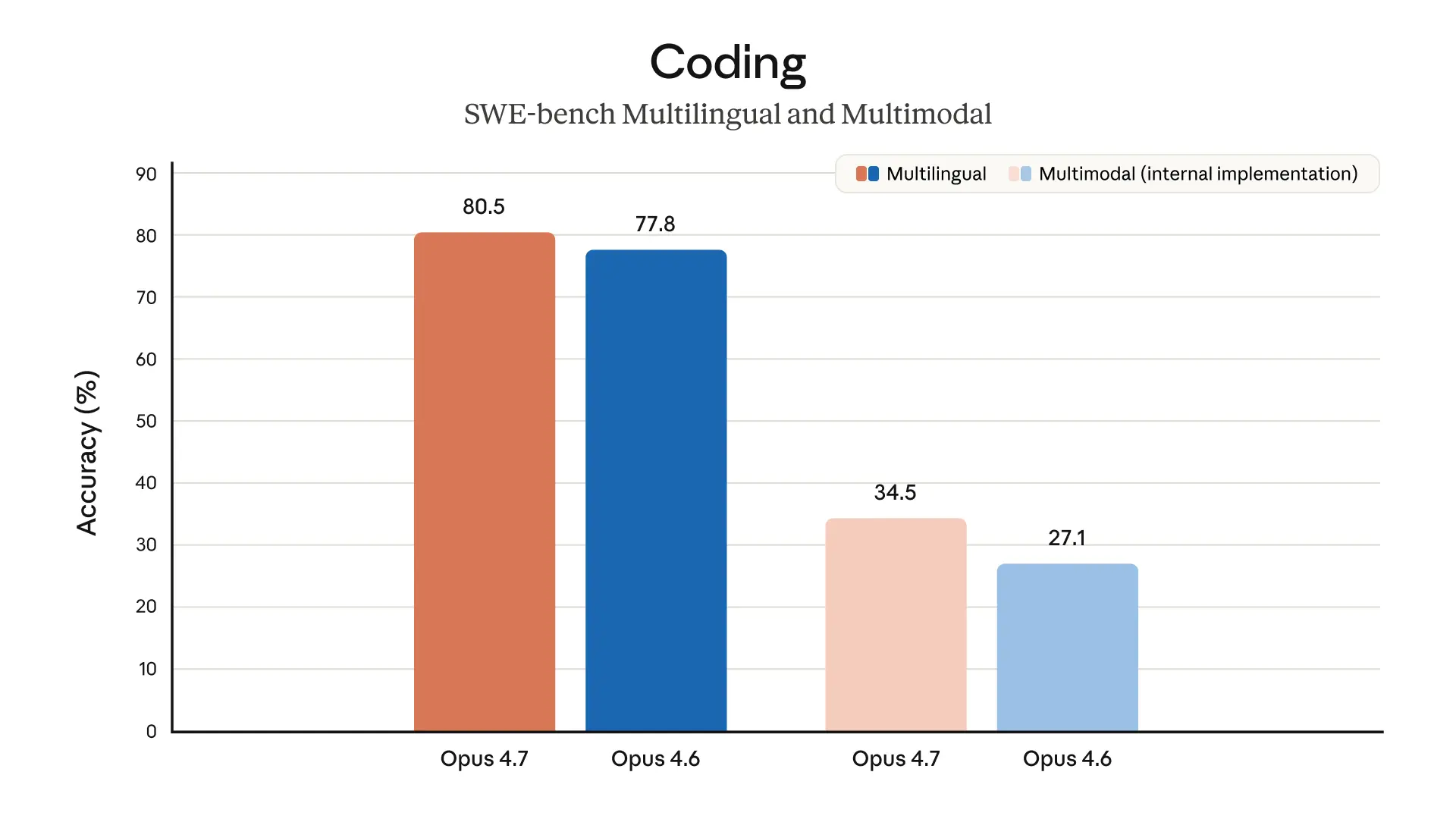
Pour les workflows multi-étapes complexes, Opus 4.7 représente une progression nette : plus 14% par rapport à Opus 4.6 avec moins de tokens et un tiers des erreurs d'outils.
C'est le premier modèle à réussir des tests de besoins implicites.
La question pertinente pour une PME n'est pas "est-ce que le modèle score mieux sur les benchmarks" mais "est-ce qu'il va moins souvent coincer au milieu d'une tâche longue".
La réponse semble être oui.
Opus 4.7 est meilleur dans l'utilisation de la mémoire basée sur le système de fichiers.
Il se souvient des notes importantes lors de travaux longs sur plusieurs sessions et les utilise pour avancer sur de nouvelles tâches nécessitant ainsi moins de contexte initial.
Pour les agents IA qui gèrent des projets sur plusieurs semaines, c'est exactement ce dont on avait besoin.
Moins de répétition, moins de reconfiguration, plus d'autonomie réelle.
La semaine dernière, Anthropic avait annoncé le Project Glasswing, mettant en évidence les risques et les avantages des modèles d'IA pour la cybersécurité.
Opus 4.7 est le premier modèle à tester de nouvelles protections cyber : ses capacités en cybersécurité ne sont pas aussi avancées que celles de Mythos Preview.
Des garde-fous détectent et bloquent automatiquement les requêtes indiquant des usages cybernétiques interdits ou à haut risque.

Pour les entreprises, c'est une bonne nouvelle.
Cela signifie qu'Anthropic teste sérieusement ses modèles avant de les exposer au grand public, et que les LLM les plus puissants ne circulent pas librement sans contrôle.
Les professionnels de la sécurité souhaitant utiliser Opus 4.7 à des fins légitimes comme la recherche de vulnérabilités, les tests d'intrusion ou le red-teaming peuvent rejoindre le Cyber Verification Program, un nouveau programme de vérification mis en place par Anthropic.
Anthropic prévient que la migration depuis Opus 4.6 peut affecter la consommation de tokens.
Le nouveau tokenizer fait qu'un même texte en entrée peut mobiliser jusqu'à 1,35 fois plus de tokens qu'auparavant.
Le modèle raisonne davantage aux niveaux d'effort élevés, ce qui augmente le volume de tokens en sortie.
En pratique :
De nouveaux outils de contrôle accompagnent le lancement : un nouveau niveau d'effort "xhigh" entre "high" et "max", des task budgets en bêta publique sur l'API permettant de guider la dépense en tokens sur les longues tâches, et dans Claude Code, la commande /ultrareview qui produit une session de revue dédiée pour repérer les bugs et problèmes de conception.
On entend souvent que les modèles d'IA se ressemblent tous de plus en plus.
Ce n'est pas tout à fait faux sur les tâches simples.
Mais sur les tâches longues, autonomes, multi-étapes, les différences deviennent très concrètes.
Le fait qu'Anthropic positionne Opus 4.7 comme le modèle "grand public" le plus capable, tout en gardant Mythos Preview pour un périmètre restreint, dit quelque chose d'important sur l'état de l'intelligence artificielle en 2026.
On est passés de "l'IA peut aider sur des tâches simples" à "l'IA peut travailler de façon autonome pendant des heures sur des projets complexes".
Ce n'est pas la même chose.
Et les entreprises qui intègrent ces modèles maintenant prennent une vraie avance opérationnelle.
Si vous suivez l'actualité de l'IA de près, vous avez sans doute entendu parler de Claude Mythos Preview, l'autre modèle d'Anthropic qui fait beaucoup parler en ce moment pour des raisons très différentes.
Opus 4.7 s'inscrit dans cette même trajectoire : des modèles de plus en plus capables, déployés avec des garde-fous de plus en plus sérieux.
Le lancement d'Opus 4.7 s'accompagne de plusieurs évolutions utiles :
Ces fonctionnalités ne feront pas les gros titres, mais elles rendent le modèle beaucoup plus utilisable en production réelle.
Si votre entreprise utilise déjà des LLM dans ses workflows, oui.
Les gains sur les tâches longues et sur la vision sont assez significatifs pour justifier une migration.
Si vous démarrez avec l'IA, c'est un bon point d'entrée : le modèle est plus rigoureux, plus prévisible, et les nouveaux outils de contrôle rendent l'intégration plus accessible.
La seule précaution : prévoyez du temps pour réajuster vos prompts et mesurer l'impact sur votre consommation de tokens avant de basculer complètement.
L'IA ne remplace pas une stratégie.
Mais un bon modèle, bien intégré, change profondément ce qu'une équipe peut accomplir.
Opus 4.7 en est un.




